1. Кэширование диска
1.1 Введение
Кэширование при записи на диск - это функция повышения производительности, появившаяся в Windows Server 2003 и Windows XP, которая позволяет операционной системе и приложениям работать быстрее, позволяя им не ждать, пока запросы на запись данных будут реально записаны на диск. Но хотя эти «отложенные записи» могут помочь Windows работать быстрее, имеется некоторый риск, связанный с ними. Этот риск обусловлен тем, что внезапный сбой оборудования, сбой программного обеспечения или перебой в подаче электроэнергии могут привести к потере кэшированных данных. В результате Windows считает, что данные были записаны на диск, в то время как на самом деле этого не произошло. Кроме того, может произойти повреждение файловой системы и/или потеря данных. Наличие резервного источника питания, такого как ИБП, может помочь устранить такие риски.
Для сценариев, где целостность данных важнее производительности, важно, чтобы кэширование диска было отключено. Одним из примеров такого сценария являются контроллеры домена Active Directory, в которых кэширование записи на диск всегда должно быть отключено для предотвращения повреждения базы данных каталога и/или потери важной информации о безопасности для домена. Фактически, когда вы продвигаете систему Windows Server на роль контроллера домена, Windows автоматически отключает функцию кэширования записи. С другой стороны, есть также некоторые приложения, в которых кэширование записи на диск всегда должно быть включено. Примером является Microsoft Exchange Server, который использует функцию кэширования Windows для своей собственной функции регистрации транзакций. Это одна из причин, почему обычно не рекомендуется развёртывать Exchange Server на контроллере домена.
1.2 Понимание кэширования записи на диск
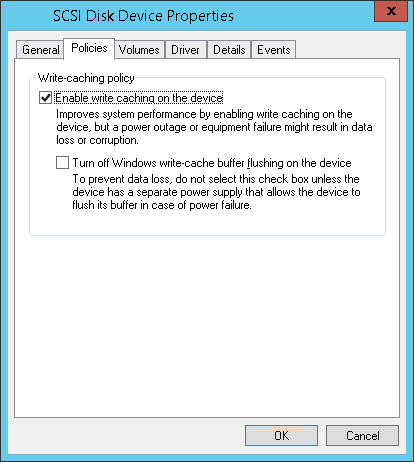
Кэширование записи на диск может быть включено или отключено для каждого тома в операционной системе Windows путём настройки параметров, доступных при открытии оснастки «Управление Компьютером», и выборе средства «Управление Дисками», нажатии правой кнопкой мышки на диск и выборе вкладки «Политики» на странице «Свойства», как показано на Рис.1 ниже:
 |
| Рисунок 1 |
Важно начать с того, что вы понимаете разницу между двумя настройками, показанными на рисунке выше. Первая настройка «Разрешить кэширование записей для этого устройства», которая включена по умолчанию, сообщает вашему оборудованию хранения данных сигнал Windows о том, что запрос на запись завершён, даже несмотря на то, что фактические данные, которые необходимо записать, ещё не были удалены из промежуточного аппаратного кэша (энергозависимое запоминающее устройство, т.е. память) в конечное место хранения (энергонезависимое запоминающее устройство, т.е. диск). Данные из запросов на запись, как правило, сохраняются только на короткий промежуток времени, так как аппаратное обеспечение хранения данных обычно сбрасывает свой кэш автоматически, когда оно находится в режиме ожидания. Некоторые команды операционной системы, включающие в себя NTF, также могут принудительно сбрасывать кэшированные данные на диск. Если происходит сбой в электропитании системы пока данные остаются в кэше, потеря данных или повреждение могут привести к сбою приложений или поломке операционной системы.
Вторая настройка конфигурации «Отключить очистку буфера кэша записей Windows для этого устройства» связана с запросами на запись, которые были помечены операционной системой как «сквозная запись», пометив её флагом ForceUnitAccess. Когда запрос на запись был помечен как сквозная запись, аппаратное обеспечение хранения данных должно гарантировать, что данные были записаны в энергонезависимое (дисковое) хранилище и не были временно сохранены в каком-либо промежуточном кэше. Корпоративное аппаратное обеспечение хранения данных может выполнить это несколькими способами. Одним из наиболее распространённых подходов является обеспечение промежуточным кэшом на аппаратном обеспечении хранения данных с резервным питанием от батареи возможности выполнения грязных (кэшированных) записей (сбрасываемых на диск в надлежащем последовательном порядке), даже когда происходит сбой питания самой серверной системы или сбой операционной системы. Если вы включите параметр «Отключить очистку буфера кэша записей Windows для этого устройства», то флаг ForceUnitAccess будет удалён из любых запросов на запись, помеченных этим флагом. Это приводит к большему использованию кэша и, следовательно, к повышению производительности записи, но эта опция должна быть активирована только при наличии ИБП, который резервирует питание для аппаратного обеспечения по всему пути ввода-вывода (или, если устройство представляет собой ноутбук с аккумулятором в нем). Из-за потенциального дополнительного риска потери данных, который может произойти, этот параметр кэширования записи по умолчанию не включён на системах Windows Server.
1.3 Сценарии для изменения параметров кэширования записи по умолчанию
Что касается первого параметра кэширования записи, то уже был упомянут пример сценария, в котором кэширование записи автоматически отключается на контроллерах домена. Но на самом деле для любого приложения, где целостность данных имеет первостепенное значение, вы можете рассмотреть возможность отключения кэша диска, чтобы гарантировать, что все данные будут записаны на диск, прежде чем подсистема хранения сообщит об успешном завершении запроса на запись. Если это так, то обязательно отключите кэширование записи как в Windows, так и в прошивке контроллера системы хранения данных.
Обратите внимание, что некоторые серверные системы имеют параметры прошивки (BIOS или UEFI), которые можно использовать, чтоб настроить промежуточное кэширование для подсистемы хранения данных, поэтому необходимо знать не только параметры Windows, чтобы настроить кэширование записи, но и надо настроить одинаково как в операционной системе, так и на контроллере системы хранения данных.
1.4 Кэширование записи на диск на виртуальных машинах
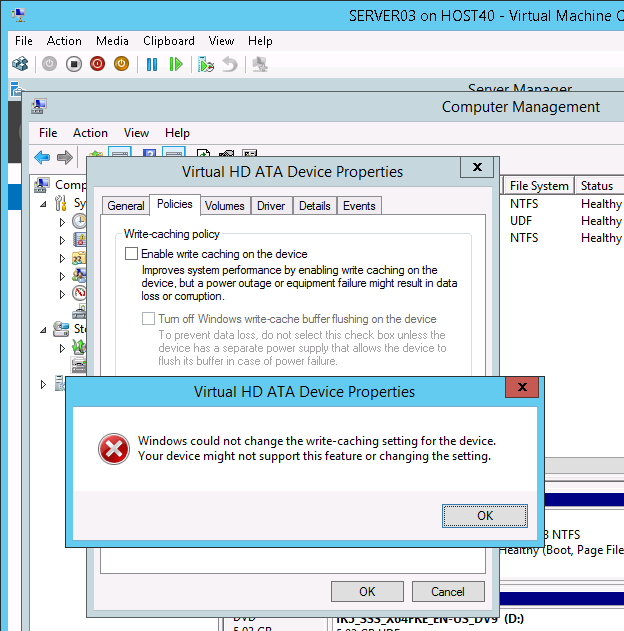
Вопрос, на котором надо сосредоточиться в конце этой части, — это влияние использования этих параметров для виртуальных машин, работающих на хостах Hyper-V. На Рис.2 показана виртуальная машина с именем SERVER03, работающая под управлением Windows Server 2012 R2, которая открыта в оснастке «Подключение к Виртуальной Машине» на хосте Hyper-V с именем HOST40, который также работает под управлением Windows Server 2012 R2. Когда мы пытаемся отключить флаг «Разрешить кэширование записей для этого устройства», чтобы отключить кэширование записи на виртуальном жёстком диске (VHD) для этой виртуальной машины, появляется диалоговое окно ошибки, сообщающее нам, что это действие недопустимо:
 |
| Рисунок 2 |
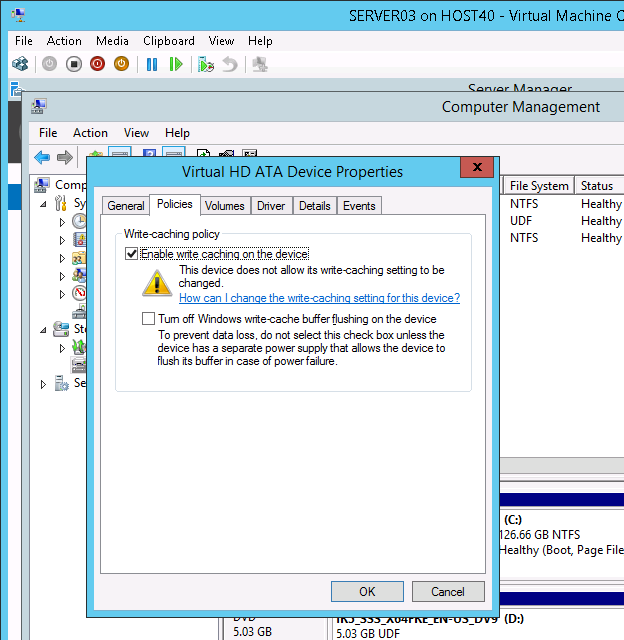
Если вы нажмёте кнопку «OK» в вышеприведённом диалоговом окне, будут восстановлены настройки кэширования записи по умолчанию и появится предупреждающее сообщение:
 |
| Рисунок 3 |
Давайте рассмотрим это более тщательно. Во-первых, совершенно очевидно, что Hyper-V не позволяет изменять параметры кэширования записи для виртуальных жёстких дисков, подключённых к виртуальным машинам. В конце концов, виртуальный жёсткий диск на самом деле не является запоминающим устройством, это просто файл (.vhd или .vhdx), хранящийся в файловой системе устройства хранения данных, используемым хостом. Поскольку это просто файл, виртуальный жёсткий диск не связан с ним какой-либо формой дискового кэша. Что на самом деле важно в этом сценарии, так это то, нужно ли включать или отключать кэширование записи на диск в физическом устройстве хранения данных, на котором хранится VHD или VHDX виртуальной машины. Тип кэширования записи, используемого физическим устройством хранения данных хоста зависит от типа устройства хранения данных, которое использует хост. Устройство хранения данных может быть внутренним жёстким диском или SSD, устройством с прямым подключением, аппаратным RAID, адаптером шины HBA оптоволоконного канала SAN и так далее.
Но если вы не можете отключить кэширование записи для этого виртуального жёсткого диска, то почему в более ранних версиях Hyper-V было возможным отключить кэширование записи на виртуальной машине с помощью приведённой выше вкладки свойств «Политики»? Ответ (как сказал один эксперт по Hyper-V в Microsoft) заключается в том, что в более ранних версиях Hyper-V была ошибка в Windows ATA-Port и стэке системы хранения данных Hyper-V, что позволило изменять параметр кэширования записи системного диска виртуальной машины, если этот системный диск был виртуальным жёстким диском, использующим виртуальный IDE (vIDE). Эта ошибка создавала у пользователей впечатление, что они могут отключить кэширование записи, чтобы улучшить целостность данных для операций записи на виртуальный жёсткий диск, но на самом деле все, что она делала, только создавала потенциал для потери и повреждения данных виртуального жёсткого диска, если физический Hyper-V хост испытывал перебои с подачей электроэнергии или незапланированную перезагрузку (см. KB2853952 для подробностей). Microsoft выпустила исправление для этой проблемы, как описано в этой статье базы знаний, но дело в том, что кэширование записи не настраивается для виртуальных жёстких дисков на виртуальных машинах и не должно.
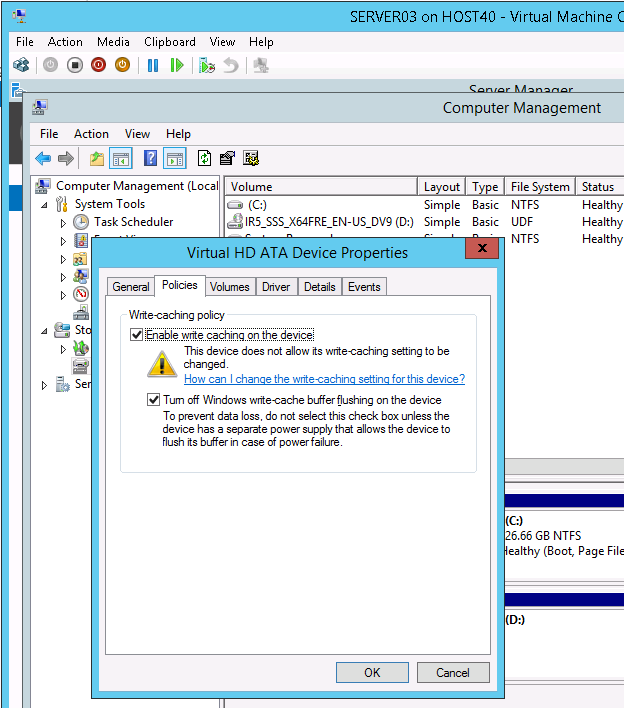
Но пока Hyper-V не позволит вам отключить кэширование записи на виртуальном жёстком диске, очистив значение параметра «Разрешить кэширование записей для этого устройства» в гостевой операционной системе виртуальной машины, Hyper-V позволяет вам изменить второй параметр «Отключить очистку буфера кэша записей Windows для этого устройства», как показано на следующем снимке экрана:
 |
| Рисунок 4 |
Почему это так и в чем смысл этого? Во-первых, помните, что это первый параметр, который определяет, включено ли кэширование записи на диск или нет. А поскольку виртуальный жёсткий диск вообще не является диском, этот параметр не имеет никакого отношения к виртуальным дискам. Но вторая настройка отличается и имеет значение, поскольку она управляет настройками включения/выключения очистки буфера кэша для диска. Когда включаете второй параметр, очистка буфера кэша, в основном, будет происходить успешно, по крайней мере, на уровне программного стека. Эти очистки буфера могут быть ресурсозатратными для определённых типов физических устройств хранения данных, таких как жёсткие диски и SATA SSD, поскольку очередь команд сбрасывается при очистке грязных данных в кэше. Очистка буфера также обычно имеет свои собственные встроенные ресурсные затраты, связанные с тем, как контроллер хранения обрабатывает их. Поэтому, когда вы выбираете этот параметр в гостевой ОС для виртуального жёсткого диска на виртуальной машине, вы можете увидеть некоторое увеличение производительности для приложений, работающих на виртуальной машине. Но всегда помните, что для целостности данных важны настройки параметров кэша диска хоста.
2. Узкое место системы хранения данных
2.1 Введение
В предыдущей части были рассмотрены параметры кэширования диска и их настройка на хостах Hyper-V и на виртуальных машинах, работающих на этих хостах. В этой части рассмотрим зависимость производительности Hyper-V от физической подсистемы хранения данных этих хостов. В частности, изучим кластеризованные хосты Hyper-V и как оптимизировать и устранять неполадки в этих системах посредством тщательного выбора аппаратного обеспечения хранения данных и настройки подсистемы хранения данных на хостах. Поскольку это широкая тема, которая в большой степени зависит от выбора поставщика оборудования систем хранения данных, рассмотрим только некоторые ключевые аспекты этой темы.
2.2 Определение узких мест системы хранения данных
Для сценария, который собираемся изучить, предположим, что у нас есть четырёхузловой кластер Windows Server 2012 R2 Hyper-V с хранилищем CSV, на котором размещается десяток виртуальных машин, работающих в качестве интерфейсных веб-серверов для крупномасштабного веб-приложения. Также предположим, что эти виртуальные машины используют функцию Virtual Fibre Channel в Windows Server 2012 R2 Hyper-V, которая позволяет подключаться к хранилищу Fibre Channel SAN из виртуальной машины через хост-адаптеры шины Fibre Channel (HBA) на узлах кластера.
Пользователи веб-приложения жаловались, что производительность приложения часто «медленна» с их точки зрения. Но «медленный» с точки зрения конечного пользователя довольно субъективный аргумент, так как более точно измерить производительность приложения? Один из показателей, на который можно посмотреть, это время отклика диска, то есть среднее время ответа томов CSV кластера. Таблица, которая связывает уровни производительности приложений с временем отклика диска и сравнивает их с показателями отдельного жёсткого диска, приведена ниже.
|
Производительность |
Среднее время отклика диска |
Примечание |
|
Очень хорошая |
Менее 5 мс |
Данный уровень производительности аналогичен производительности выделенного SAS диска |
|
Хорошая |
5-10 мс |
Данный уровень производительности аналогичен производительности выделенного SATA диска |
|
Удовлетворительная |
10-20 мс |
Данный уровень производительности обычно неприемлем для интенсивных рабочих нагрузок ввода/вывода, таких как при работе с базами данных |
|
Низкая, необходимо обратить внимание |
20-50 мс |
Данный уровень производительности может вызывать у пользователей ощущение медленной работы приложения. |
|
Очень низкая, «узкое место» |
Более 50 мс |
Данный уровень производительности, как правило, заставляет пользователей жаловаться |
Если среднее время отклика диска составляет более 20 мс, следует выполнить мониторинг производительности системы чтобы попытаться определить причину проблемы. Счётчики производительности, которые обычно должны использоваться для мониторинга производительности дисков на хостах Hyper-V, таковы:
\Logical Disk(*)\Avg. sec/Read
\Logical Disk(*)\Avg. sec/Write
Обычно лучше сосредоточиться на счётчиках логических дисков вместо счётчиков физических дисков, поскольку приложения и службы, работающие на Windows Server, используют логические диски, представленные в виде букв дисков, тогда как фактический физический диск (LUN), представляемый операционной системе, может состоять из нескольких физических дисков, организованных в дисковый массив.
2.3 Устранение проблем с производительностью дисковой подсистем
После того, как было определено, что кластерный хост Hyper-V испытывает проблемы с производительностью из-за узкого места в дисковой подсистеме, существует несколько различных шагов, которые можно предпринять, чтобы попытаться разрешить или смягчить эту проблему. Шаги, описанные в этом разделе, не являются исчерпывающими, но часто могут помочь в случаях, когда «приложение работает медленно».
2.3.1 Следуйте рекомендациям поставщика системы хранения данных
Первое, что, вероятно, следует сделать, когда было определено, что хранилище является узким местом производительности для кластера Hyper-V, состоит в том, чтобы проверить, имеет ли поставщик хранилища документ с рекомендациями, относящийся к различным сценариям Hyper-V. Поставщики систем хранения данных часто создают такую документацию на основе хорошо понятых шаблонов ввода/вывода для разных типов рабочих нагрузок, и если можно точно сопоставить документацию поставщика типу рабочей нагрузке вашего собственного приложения, работающего на кластерных хостах Hyper-V, то следует убедиться, что вы придерживаетесь различных рекомендаций, которые поставщик хранилища предлагает для такого типа нагрузки.
Следуя рекомендациям поставщика хранилища, можно обнаружить, что вы решили или хотя бы смягчили свою проблему с производительностью. С другой стороны, можно обнаружить небольшое или полное отсутствие улучшения, следуя советам поставщика хранилища. Это связано с тем, что профилирование хранилищ в лабораторной среде иногда плохо переводится в реальный мир, где пользователи могу вести себя непредсказуемо, а многоуровневые приложения могут быть более сложными в своём поведении, чем это обычно наблюдается с образцовыми приложениями.
2.3.2 Используйте более быстрые диски в вашем массиве хранения данных
Используя программное обеспечение вашего поставщика хранилища, вы должны контролировать нагрузку на массив хранения данных, чтобы увидеть, является ли средняя нагрузка неприемлемо высокой. Если вы так считаете, то единственный очевидный шаг, который можно предпринять, - заменить более медленные диски на более быстрые, например, диски 15k SAS (c количеством оборотов шпинделя 15 000 в минуту). В общем случае предпочтение следует отдавать дискам SAS над дисками SATA, если вы хотите обеспечить оптимальную производительность массива хранения данных. Диски 10k или 15k SAS всегда предпочтительнее любого быстрого SATA-диска.
2.3.3 Используйте RAID 10 вместо RAID 5
Традиционно RAID 5 (чередование с контролем чётности) был самым популярным уровнем RAID, используемым для серверов. С другой стороны, RAID 10 (зеркалирование с чередованием) использует чередующийся массив дисков, которые зеркалируются на второй идентичный набор чередующихся дисков. RAID 10 обеспечивает наилучшую производительность чтения и записи по сравнению с другими уровнями RAID, но только за счёт необходимости в два раза большего количества дисков для заданного общего объёма хранилища. Поэтому, если вы можете позволить себе выделить дополнительные ресурсы на хранение данных кластеру, то используйте RAID 10 для хранилища, используемого виртуальными машинами через виртуальное подключение Fibre Channel. В любом случае, как правило, не надо использовать RAID 5 или RAID 6 (RAID с двойной чётностью) для хранения, используемого виртуализированными рабочими нагрузками, поскольку это не подходящее решение из-за случайного доступа на запись. Однако, могут быть исключения из этого правила, но единственным способом их правильной идентификации является мониторинг производительности на чтение/запись для разных уровней RAID для приложения, чтобы можно было выбрать наиболее подходящий уровень RAID для конкретного сценария.
Убедитесь также, что у вас столько RAID-массивов, сколько узлов в кластере хостов Hyper-V. Другими словами, наличие четырехузлового кластера означает, что должно быть четыре массива RAID, настроенных в массиве хранения данных, то есть один RAID-массив для каждого хоста.
2.3.4 Проверьте конфигурацию контроллера системы хранения данных
Убедитесь, что микропрограмма контроллера системы хранения данных обновлена до последней версии от поставщика хранилища, чтобы обеспечить оптимальную производительность массива хранения данных. Если контроллер системы хранения данных сильно загружает CPU, то диски в массиве хранения данных, вероятно, слишком медленные и должны быть обновлены на более быстрые диски (и, если возможно, на тип SAS, как упоминалось ранее).
Кроме того, если не было включено кэширование записи на контроллере системы хранения данных, возможно, это следует сделать, поскольку это может увеличить пропускную способность ввода/вывода системы на 20% и более, в зависимости от вашей рабочей нагрузки и уровня RAID, который был реализован. Конечно, есть и другие соображения, связанные с кэшированием записи, см. Часть №1 этой статьи для получения дополнительной информации по этому вопросу.
2.4 Краткий итог части №2
В следующих частях статьи рассмотрим другие советы по повышению производительности системы хранения данных в средах Hyper-V.
3. Глубина очереди системы хранения данных
В предыдущих частях этой статьи мы начали с изучения настроек кэширования диска и их настройки на хостах Hyper-V и на виртуальных машинах, работающих на этих хостах. Затем была рассмотрена зависимость производительности Hyper-V от физической подсистемы хранения данных кластерных хостов Hyper-V и способы оптимизации и устранения неполадок в этих системах с помощью разумного выбора аппаратного обеспечения системы хранения данных. Также мы начали обсуждение того, как можно настроить подсистему хранения данных на кластерных хостах, но эта тема, естественно, сильно зависит от выбора поставщика оборудования системы хранения данных. В этой части продолжим предыдущую дискуссию, рассмотрев тему глубины очереди системы хранения данных и её потенциальное влияние на производительность хостов Hyper-V и виртуальных машин, работающих на этих хостах.
3.1 Проверка сценария
Продолжим базировать обсуждение на сценарии, изложенном в предыдущей части статьи, а именно на четырехузловом кластере Windows Server 2012 R2 Hyper-V с хранилищем CSV, в котором размещается дюжина виртуальных машин, работающих в качестве интерфейса веб-серверов для крупномасштабного веб-приложения. Виртуальные машины также используют виртуальный адаптер Fibre Channel в Windows Server 2012 R2 Hyper-V, который позволяет подключаться к хранилищу Fibre Channel SAN из виртуальной машины через хост-адаптеры шины Fibre Channel на узлах кластера. В предыдущей части было рассмотрено использование времени отклика диска, то есть среднее время отклика томов CSV кластера, как способ измерения производительности веб-приложений. Затем было предположено, что если измеренная производительность ниже определённого порогового значения (было выбрано 20 мс в качестве разумного уровня отсекания), то администратору кластера необходимо предпринять какие-то корректирующие действия для устранения узкого места в системе хранения данных и попытаться повысить производительность приложений. Пять примеров возможных рекомендаций, которые были определены:
- Следуйте рекомендациям поставщика системы хранения данных;
- Используйте более быстрые диски в массиве хранения данных;
- Используйте RAID 10 вместо RAID 5;
- Убедитесь, что микропрограмма контроллера системы хранения данных была обновлена до последней версии;
- Включите кэширование записи на контроллере системы хранения данных (но просмотрите Часть №1 для некоторых рекомендаций в этой связи).
Однако, касательно вышеуказанной первой рекомендации, одна из проблем, часто обсуждаемая в документации на массивы хранения данных, заключается в изменении глубины очереди, чтобы попытаться оптимизировать производительность. Давайте рассмотрим эту проблему более подробно.
3.2 Понимание глубины очереди
Массивы хранения данных, подключаемые по протоколу Fibre Channel, часто используются в качестве систем хранения данных для кластеров Hyper-V. В типичном примере массив хранения данных подключён к одному или нескольким коммутаторам SAN для формирования коммутационной фабрики. В порты коммутаторов SAN подключаются сервера посредством хост-адаптеров шины (HBA). Одним из настраиваемых параметров хост-адаптера (также называемого контроллером хранения) является глубина очереди. Этот параметр указывает количество запросов ввода/вывода, которые HBA может поставить в очередь для обработки. Глубина очереди на HBA определяется на основе количества LUN. Если очередь на контроллере хранения заполняется, он начинает отбрасывать последующие запросы на чтение или запись. Затем через некоторое время до хоста (то есть приложения, запущенного на узле) предпринимается попытка повторного запроса ввода/вывода.
Когда вы настраиваете глубину очереди на хосте (то есть на HBA в хостах Hyper-V), необходимо попытаться следовать следующим общим рекомендациям:
- Настройте параметр глубины очереди одинаково на всех хостах кластера, чтобы обеспечить равный доступ к пулу носителей в сети хранения данных;
- Глубина очереди HBA должна быть больше или равна числу шпинделей, к которым подключается хост (для массива хранения данных на жёстких дисках);
- В общем, чем больше кластер хостов (и чем больше запущено на нем виртуальных машин), тем больше должно быть значение глубины очереди;
- Однако обычно существует уровень, за которым увеличение глубины очереди не приводит к дальнейшему увеличению производительности операций ввода/вывода и фактически начинает быть контрпродуктивным, особенно для определённых рабочих нагрузок, таких как SQL Server;
- Не допускайте, чтобы глубина очереди на хостах (т.е. на HBA) превышала глубину очереди, настроенную на портах SAN, к которым подключены HBA.
Однако это лишь основные рекомендации, в реальности, где может быть несколько виртуальных машин, работающих на каждом хосте и несколько плат HBA на каждом хосте, ситуация может немного усложниться.
3.3 Определение оптимальной глубины очереди
В общем случае осуществлять выбор оптимальной глубины очереди для HBA на кластерных хостах Hyper-V в среде SAN лучше всего, консультируясь с документацией поставщика SAN, т.к. карты HBA обычно предоставляются тем же поставщиком. В качестве примера (хотя и взятого из мира VMware вместо Microsoft), один эксперт рекомендует для определения глубины очереди в сценарии, где у вас есть несколько хостов ESXi, использующих хранилище SAN, применять следующую формулу:
Port-QD = ESXi Host 1 (P * QD * L) + ESXi Host 2 (P * QD * L) ….. + ESXi Host n (P * QD * L)
Здесь «Port-QD» представляет глубину очереди целевого порта, «P» представляет количество путей до хоста, подключённых к целевому порту массива, «L» представляет количество LUN, предоставленных хосту через целевой порт массива, а «QD» равно глубине очереди LUN на хосте.
Имеет ли Microsoft аналогичную формулу для вычисления глубины очереди в средах кластера хостов Hyper-V? К сожалению, нет, они просто оставляют поставщику хранилища (SAN) предоставление формулы. В качестве примера, Hitachi имеет PDF-документ под названием «Рекомендации для Microsoft SQL Server на платформе дисковых массивов Hitachi Universal Storage Platform VM», в котором говорится следующее касательно параметров глубины очереди HBA:
«Слишком маленькая глубина очереди может искусственно ограничить производительность приложения, а слишком высокое её значение может привести к небольшому снижению производительности ввода/вывода. Правильная настройка глубины очереди позволяет контроллерам системы хранения данных Hitachi оптимизировать множество операций ввода/вывода на физический диск. Это может обеспечить значительное улучшение ввода/вывода и сократить время отклика.»
Затем они предоставляют следующую формулу для расчёта глубины очереди:
2048 ÷ общее количество LU, представленных через порт внешнего интерфейса = глубина очереди HBA на хост
Однако коллега, который на самом деле проверил это на кластерной среде хостов Hyper-V, на которой работает SQL Server, обнаружил, что, хотя формула рекомендовала использовать глубину очереди 128, проверенная производительность была в действительности лучше при использовании глубины очереди 64. Таким образом, другими словами, следует рассматривать такие формулы как рекомендации для начальной настройки глубины очереди, а не как неукоснительные правила.
3.4 Углубляясь дальше
Немного глубже рассмотрим предыдущее утверждение, что существует уровень, за которым увеличение глубины очереди HBA ведёт к снижению производительности операций ввода/вывода и может нанести ущерб производительности приложений, работающих на кластере. Дело в том, что если запоминающие устройства в массиве медленные, то увеличение глубины очереди в действительности только увеличивает длину канала ввода/вывода хранилища, но не делает ее быстрее. Другими словами, если приложение медленно реагирует или не отвечает из-за узкого места в системе хранения данных, то проблема, скорее всего, связана не с настройкой длины очереди, а с медленными запоминающими устройствами (или с субоптимальной конфигурацией RAID). Кроме того, увеличение глубины очереди на стороне хоста (кластера) без учёта конфигурации со стороны хранилища (SAN) может просто привести к переполнению массива хранения до такой степени, что производительность начнёт ухудшаться.
Поэтому, если вы отслеживаете глубину очереди на HBA и видите заполнение очередей, может возникнуть соблазн увеличить глубину очереди на коммутаторах SAN для удовлетворения большего количества запросов ввода/вывода от HBA на хостах. Но в то время как это может привести к меньшему наращиванию в очередях HBA, фактически вы можете увидеть снижение производительности приложений, потому что операции ввода/выводы теперь могут зависнуть в контроллерах системы хранения данных.
3.5 Основная суть
Основная суть заключается в том, что независимо от того, что вы делаете касательно настройки глубины очереди, либо на стороне HBA, либо на стороне SAN, вам нужно проверять эффект каждый раз, когда вы вносите изменения. Это также означает, что каждый раз, когда вы добавляете дополнительный хост, или другой HBA к хосту, или более быстрые диски в массиве вам нужно вернуться назад, и начать все заново и протестировать производительность вашей среды. Таким образом, лучший подход, помимо общих рекомендаций, перечисленных выше, и попыток понять рекомендации поставщика системы хранения данных, вероятно, состоит в том, чтобы начать с параметров глубины очереди по умолчанию и делать по одному изменению за раз, чтобы увидеть, улучшается или ухудшается производительность приложения. И действительно, вам нужно беспокоиться только о настройке глубины очереди, если вы видите тревожное время отклика диска более чем на пару секунд. В противном случае, производительность приложения, вероятно, достаточно хороша, чтобы обеспечить «достаточно хорошее» удовлетворение для большинства клиентов, поэтому, зачем тратить время и энергию, пытаясь выжать ещё одну секунду из времени отклика? Лучше иметь дело с более насущными проблемами, такими как обеспечение безопасности учётных данных клиента и финансовых отчётов, рассмотрение государственных требований соблюдения конфиденциальности для разных клиентских сегментов и т. д.
3.6 Краткий итог части №3
В следующих частях статьи рассмотрим некоторые другие советы по повышению производительности системы хранения данных в средах Hyper-V.
4. Кластеризованные рабочие нагрузки SQL Server
В предыдущих частях этой статьи было рассмотрено несколько аспектов оптимизации Hyper-V, включая то, как надо настраивать параметры кэширования диска как на хостах Hyper-V, так и на виртуальных машинах, работающих на этих хостах; как производительность Hyper-V может зависеть от физической подсистемы хранения данных кластерных хостов Hyper-V и как оптимизировать и устранять неполадки в производительности этих систем посредством разумного выбора аппаратного обеспечения системы хранения данных; как глубина очереди системы хранения данных может потенциально повлиять на производительность виртуализированных рабочих нагрузок на хостах Hyper-V. Когда рассматривалась эта тема, было упомянуто о том, что обычно существует уровень, выше которого увеличение глубины очереди приводит к снижению производительности операций ввода/вывода и фактически может стать контрпродуктивным, особенно для определённых рабочих нагрузок, таких как Microsoft SQL Server.
В этой части рассмотрим, как можно дальше оптимизировать производительность Hyper-V при размещении кластеризованных рабочих нагрузок SQL Server. Это важный вопрос, потому что SQL Server в чем-то отличается от других видов рабочих нагрузок, и это может сделать виртуализацию SQL Server нетривиальной задачей по сравнению, например, с виртуализацией контроллера домена, файлового сервера или веб-сервера, особенно когда рабочая нагрузка SQL Server кластеризована.
4.1 Варианты систем хранения данных для виртуализации SQL Server
Начнём с рассмотрения различных вариантов систем хранения данных, доступных при виртуализации SQL Server для высокой доступности на Hyper-V. В основном, имеется два способа решения этой проблемы:
- Использование общего хранилища с Отказоустойчивой Кластеризацией;
- Использование Групп Доступности SQL Server.
Кратко рассмотрим эти два разных подхода.
4.2 Использование Отказоустойчивой Кластеризации
Отказоустойчивая кластеризация является стандартным решением Microsoft для обеспечения высокой доступности и масштабируемости для большинства рабочих нагрузок Windows Server. Операционная система Windows Server 2012 R2 представила ряд существенных улучшений для отказоустойчивой кластеризации, а процедура установки отказоустойчивого кластера SQL Server хорошо документирована в Microsoft TechNet, а также имеется отличная инструкция, созданная египетским ИТ-специалистом Мохамедом Эль Манахли, которая может быть использована для быстрого создания лабораторной среды тестирования и разработки.
При установке SQL Server на отказоустойчивый кластер в Windows Server 2012 R2 также можно выбирать между двумя разными субподходами, а именно: Виртуальный VHDX или Виртуальный Fibre Channel. Например, можно установить экземпляры отказоустойчивого кластера с общими виртуальными жёсткими дисками (Shared VHDX) на серверах масштабирования файловых серверов Windows (SOFS) с использованием карт с функцией удалённого доступа к памяти (RDMA.) Общий VHDX — это функция, которая ранее была представлена в Windows Server 2012 и позволяет использовать файл виртуального жёсткого диска (VHDX) в качестве общего хранилища для гостевого кластера, то есть отказоустойчивого кластера, созданного на виртуальных машинах. Общий VHDX предназначен для защиты таких служб приложений, как SQL Server, работающих на виртуальных машинах, и делает развёртывание отказоустойчивых кластеров намного проще, поскольку можно использовать общие папки SMB в качестве общего хранилища вместо необходимости использовать массивы хранения данных iSCSI или FiberChannel.
Другим способом, при помощи которого можно установить SQL Server на отказоустойчивые кластеры, является использование виртуального Fibre Channel и SAN. Виртуальный Fibre Channel позволяет напрямую подключать такие приложения, как SQL Server, работающий на виртуальных машинах, к хранилищу Fibre Channel в сети. Это позволяет использовать существующие инвестиции в технологии SAN для поддержки рабочих виртуализированных нагрузок с помощью Hyper-V.
4.3 Использование Групп Доступности
Альтернативный подход, помимо Отказоустойчивой Кластеризации, обеспечивающий высокую доступность и масштабируемость для SQL Server, заключается в использовании Групп Доступности Always On (или просто Групп Доступности). Эта функция была впервые представлена в SQL Server 2012, и это альтернатива промышленного уровня зеркалированию баз данных, чтобы обеспечить их доступность в любое время.
4.4 Возможно лучший подход
Подход посредством Общего VHDX является наиболее привлекательным, когда есть необходимость обеспечить высокую доступность для рабочих нагрузок SQL Server, работающего на Hyper-V. Причины для этого следующие:
- Когда используется Общий VHDX в качестве общего хранилища для виртуализованных отказоустойчивых кластеров, то будет отсутствовать работа по администрированию хранилища, касательно гостевой операционной системы;
- Использование Общего VHDX также означает, что не нужно будет выполнять конфигурацию хранилища на каждой виртуальной машине на системах хостов Hyper-V.
Но наиболее привлекательный подход с точки зрения функциональности не всегда является наилучшим подходом с точки зрения производительности. Например, хотя Общий VHDX предоставляет ряд преимуществ для отказоустойчивых кластеров SQL Server виртуальных экземпляров, это может привести к перенаправленным операциям ввода/вывода в определённых сценариях, что можно повлиять на производительность. Например, один консультант по SQL Server сообщал, что он видел, что Общий VHDX, реализованный на общем томе кластера (CSV), привёл к некоторым значительным проблемам производительности, связанным с операциями ввода/вывода, когда операции ввода/вывода перенаправлены, и поэтому он советует соблюдать осторожность при следовании этому подходу. Виды сценариев, в которых возникают такие проблемы с производительностью, обычно используют Общий VHDX с локальным блочным хранилищем, например, с массивами хранения данных Fibre Channel или iSCSI, что приводит к перенаправлению операций ввода/вывода.
Однако есть способы обхода, которые могут быть реализованы, чтобы смягчить эти типы проблем с производительностью. Например, обеспечение достаточной пропускной способности внутрикластерной связи является одним из ключевых предложений для достижения того, что перенаправление операций ввода/вывода не окажет отрицательного влияния на производительность виртуализованного кластера SQL Server. Это означает, например, использование 10Гб сетевых карт на серверах вместо более дешёвых 1 Гб сетевых карт, которые валяются в отделе. Или, еще лучше, получить сетевые карты с поддержкой RDMA, и все будет настолько хорошо, насколько это может быть, касаемо производительности.
Необходимо также иметь в виду, что не только скорость сетевых адаптеров может влиять на производительность отказоустойчивого кластера, но и остальная часть сетевой инфраструктуры, которая используется для подключения узлов кластера друг к другу, к общему хранилищу и к клиентам, использующим кластеризованные приложения. Плохо спроектированная кластерная сеть часто может ограничить работу отказоустойчивого кластера на оптимальных уровнях. Если используется Общий VHDX в такого рода системах, то необходимо убедиться, что сетевые соединения отказоустойчивого кластера оптимизированы, выполнив следующие действия:
- Использовать RDMA-совместимые 10 Гб сетевые карты;
- Использовать масштабирование на стороне приёма (RSS), которое означает, что межсетевые соединения не должны быть частью виртуального коммутатора;
- Настроить очереди RSS на максимальные поддерживаемые значения;
- Настроить схему управления питанием хоста Hyper-V на Высокую Производительность;
- Отключить NetBIOS, если он не требуется.
Также можно попробовать настроить буферы передачи и приёма на сетевых адаптерах, чтобы проверить, может ли это повысить производительность. Можно попробовать использовать Кадры Крупного Размера (Jumbo Frames), хотя, как кажется, вердикт, что это может помочь в конкретном сценарии, по-прежнему отсутствует.
4.5 Некоторые другие соображения
Но не только сеть может быть основным узким местом производительности кластера SQL Server. Вы можете использовать Общий VHDX с локальным блочным хранилищем в SAN и иметь надёжную схему сети, но позже оказывается, что SAN сама становится узким местом. Это связано с тем, что SAN — это унаследованная технология, у которой есть сложный стек, производительность которого зависит от скорости передачи данных жёсткими дисками, скорости передачи данных LUN, скорости порта контроллера системы хранения данных и скорости порта коммутатора. Затем нужно разобраться с хостами Hyper-V и скоростью их порта HBA, скоростью передачи данных процессором и скоростью упреждающего чтения кэша.
Еще один недостаток использования Общего VHDX заключается в том, что в своей текущей реализации в Windows Server 2012 R2 он не полностью совместим с функцией Реплика Hyper-V, которая была представлена в Windows Server 2012. Реплика Hyper-V обеспечивает механизм встроенной репликации для асинхронного копирования виртуальных машин с первичной площадки на вторичную. Таким образом, Реплика Hyper-V может стать ценным дополнением к стратегиям аварийного восстановления, но она не будет полностью совместима с Общим VHDX до Windows Server 2016. До тех пор, однако, Microsoft не поддерживает использование Реплики Hyper-V с любым типом гостевой кластеризации. Но это проблема аварийного восстановления, а не проблема производительности, и мы сосредоточимся здесь на оптимизации производительности Hyper-V для кластеров SQL Server.
Группы Доступности, с другой стороны, являются встроенным решением SQL Server для обеспечения высокой доступности, но у них также есть проблемы, связанные с производительностью. Например, всякий раз, когда применяются Группы Доступности, можно рассчитывать на то, что будет использоваться в два раза большее хранилище, а также будет выполняться в два раза больше операций ввода/ввода в секунду (IOPS) по сравнению с тем, если не использовать эту функцию.
4.6 В заключение...
Оптимизация производительности Hyper-V для сложного сценария, такого как кластеризованный SQL Server, является нетривиальной, но увлекательной задачей для решения. На данный момент существует не слишком много ресурсов по этой тематике, возможно, потому, что платформы Windows Server Hyper-V и SQL Server продолжат развиваться в грядущих версиях 2016. В результате можно снова вернуться к этой теме в ближайшем будущем.
5. Управление электропитанием
В предыдущих частях статьи был рассмотрен ряд следующих аспектов оптимизации Hyper-V: параметры кэширования диска должны быть настроены как на хостах Hyper-V, так и на виртуальных машинах, работающих на этих хостах; как производительность Hyper-V может зависеть от физической подсистемы хранения данных кластеризованных хостов Hyper-V и как оптимизировать и устранять неполадки в производительности на этих системах посредством разумного выбора аппаратного обеспечения СХД; как глубина очереди системы хранения данных может потенциально повлиять на производительность виртуализированных рабочих нагрузок на хостах Hyper-V; и как можно оптимизировать производительность Hyper-V при размещении кластеризованных рабочих нагрузок SQL Server. В части №4 также было упомянуто, что, если используется Общий VHDX для отказоустойчивого кластера SQL Server, можно гарантировать, что сетевые соединения отказоустойчивого кластера оптимизированы с помощью:
- Использования RDMA-совместимых 10 Гб сетевых карт;
- Использования масштабирования на стороне приёма (RSS), которое означает, что межсетевые соединения не должны быть частью виртуального коммутатора;
- Настройки очередей RSS на максимальные поддерживаемые значения;
- Настройки схемы управления питанием хоста Hyper-V на Высокую Производительность;
- Отключения NetBIOS, если он не требуется.
5.1 Параметры электропитания гостевой системы, в основном, неактуальн
В качестве отправной точки необходимо понимать, что гостевая операционная система на виртуальной машине, запущенной на хосте Hyper-V, не имеет прямого доступа к физическому оборудованию хоста. В результате любые параметры электропитания, которые настраиваются в гостевой операционной системе, не должны влиять на работу виртуальной машины или хоста. Это связано с тем, что операционная система хоста вместе со своим гипервизором работают в связке, чтобы управлять фактическими функциями управления электропитания платформы. В результате внесение изменений в параметры электропитания в операционной системе хоста может повлиять на производительность как системы хоста, так и любых виртуальных машин, работающих на хосте.
Теперь есть одно исключение, а именно виртуальное (или синтетическое) состояние бездействия гостевой операционной системы, которое было введено в Windows Server 2008 R2 как низкоуровневая функция управления электропитанием. Состояние бездействия виртуального гостевой ОС используется функцией Интеллектуального Распределения Тактов (Intelligent Timer Tick Distribution, ITTD), обеспечивающей более длительное нахождение процессоров и ядер в спящем режиме. Это достигается за счёт того, что прерывания таймера не обрабатываются всеми ядрами процессора, когда в системе происходит периодическое прерывание таймера (прерывания таймера обрабатываются одним ядром), и в виртуализированных системах это может помочь реализовать снижение трафика прерываний таймера и увеличить длительность периодов бездействия системы. Общее влияние от использования виртуального состояния бездействия гостевой ОС, наряду с другими функциями, такими как парковка ядер и объединение таймеров, привело к повышению энергоэффективности Windows Server 2008 R2 Hyper-V по сравнению с Windows Server 2008 Hyper-V, и эти функции и возможности остаются в Hyper-V в Windows Server 2012 и 2012 R2.
Теперь, если виртуальное состояние бездействия гостевой ОС отключено в гостевой операционной системе, то это часто влияет на производительность виртуальной машины, но обычно это приводит к снижению производительности, поэтому не рекомендуется отключать это состояние. Однако, внесение изменений высокого уровня в параметры питания гостевой ОС, например, при переходе от плана электропитания «Высокая Производительность» к плану «Сбалансированный», скорее всего, не будет иметь ощутимого влияния на производительность рабочей нагрузки, размещаемой на виртуальной машине, поскольку гостевая операционная система не может управлять состояниями производительности процессора хоста, такими как функция Intel SpeedStep.
5.2 Параметры электропитания хоста такие же, как и для не-Hyper-V систем
Рекомендации Microsoft по настройке параметров электропитания для хостов Hyper-V в основном такие же, как для Windows Server без установленной роли Hyper-V. Лучшее руководство по этой теме можно найти в документе «Windows Server 2012 R2 - Рекомендации по настройке производительности сервера». Инсайдеры в Microsoft сообщают, что менеджер электропитания ядра в операционной системе хоста в системе Hyper-V работает в связке с гипервизором, и что есть несколько незначительных отличий в том, как функции управления электропитанием работают с процессором, когда работает гипервизор по сравнению с тем, когда он не запущен, но эти различия незаметны и не документированы публично.
5.3 Виртуальные машины SQL Server являются возможным исключением
Некоторые инсайдеры Microsoft также сообщали, что отдельным клиентам иногда давали рекомендации, заключающиеся в том, что если есть виртуальные машины с установленным SQL Server, то необходимо установить в гостевой ОС параметры электропитания соответствующими параметрам хоста. Поэтому, если высокая производительность является рекомендуемым планом питания для хостов Hyper-V, на которых выполняются виртуализованные рабочие нагрузки SQL Server, тогда виртуальные машины на этом хосте также должны иметь план управления электропитанием «Высокая производительность». Тем не менее, есть противоречивые заявления от инсайдеров о том, вносит ли это какие-либо изменения в производительность SQL Server. SQL Server как продукт очень чувствителен к настройкам электропитания, когда развёрнут на выделенном физическом сервере. Поэтому основным для этого сценария является проверка того, есть ли разница в производительности, когда план электропитания в гостевой ОС меняется с «Сбалансированный» на «Высокая Производительность».
5.4 Hyper-V и планы электропитания ВIOS
В качестве последнего упоминания, важно знать, что современные серверы могут иметь параметры планы электропитания, которые можно настраивать в BIOS сервера. Это определённо относится к серверам Dell и HP.
6. Производительность сети — Мост для Центра Обработки Данных
В предыдущих частях статьи были рассмотрены различные аспекты оптимизации производительности Hyper-V, в том числе параметры кэширования дисков на хостах Hyper-V и виртуальных машинах, узкие места системы хранения данных на кластерах хостов, глубина очереди хранения, кластеризованные рабочие нагрузки SQL Server и параметры управления электропитанием. В этой части рассмотрим некоторые проблемы, связанные с мониторингом производительности сети хостов Hyper-V и кластера хостов в корпоративных средах.
6.1 Обзор основных концепций
Прежде чем углубиться в эту тему, начнём с рассмотрения некоторых базовых сетевых концепций, которые обычно имеют значение при рассмотрении хостов Hyper-V, развёрнутых в корпоративных средах. Эти концепции включают в себя Качество Обслуживания (QoS), Мосты для Центра Обработки Данных (DCB), Прямую Передачу Данных (ODX), Объединение Сетевых Карт Windows и Конвергентные Сетевые Адаптеры (CNAs).
Качество Обслуживания (QoS) — В целом это относится к любым технологиям, используемым для управления сетевым трафиком, таким образом, чтобы они могли удовлетворять Соглашениям об Уровне Обслуживания и/или улучшить возможности опыта взаимодействия эффективным способом. Используя QoS для установки приоритетов различным типам сетевого трафика, можно обеспечить доставку критически важных приложений и сервисов в соответствии с SLA и оптимизировать производительность пользователей. Hyper-V в Windows Server 2012 позволяет указать верхнюю и нижнюю границы пропускной способности сети, используемой виртуальными машинами. В Windows Server 2012 R2 также появилось Качество Обслуживания Хранилища (SqoS), новая функция файлового хранилища, которая активируется на уровне VHDX и позволяет ограничить максимальное количество Операций Ввода/Ввывода, разрешённое для виртуального диска на хосте Hyper-V. Оно также может позволить устанавливать триггеры для отправки уведомлений, если для виртуального диска не выполняется заданный минимум IOPS.
Мосты для Центра Обработки Данных (DCB) — Это стандарт IEEE, который позволяет распределять пропускную способность на основе аппаратного обеспечения для определённых типов сетевого трафика. Это означает, что DCB — еще одна технология QoS. Сетевой адаптер, поддерживающий DCB, может быть полезным в облачных средах, где он может включать хранилище, управление данными и другие виды трафика в одну и ту же базовую физическую сеть таким образом, чтобы гарантировать каждому типу трафика достаточную долю полосы пропускания. Windows Server 2012 поддерживает DCB при условии, что в сети есть как сетевые карты Ethernet с поддержкой DCB, так и Ethernet-коммутаторы с поддержкой DCB.
Прямая Передача Данных (ODX) — Это функциональность в Windows Server 2012, которая позволяет массивам хранения данных, поддерживающим ODX, обходить компьютер-хост и напрямую передавать данные внутри или между совместимыми устройствами хранения данных. В результате минимизируется время ожидания, максимизируется пропускная способность массива и уменьшается использование ресурсов, таких как, потребление процессора и использование сети на компьютере-хосте. Например, используя совместимые с ODX массивы хранения данных, доступ к которым можно получить через iSCSI, Fibre Channel или общие папки SMB 3.0, виртуальные машины, хранящиеся в массиве, могут быть импортированы и экспортированы гораздо быстрее, чем без наличия функциональности ODX.
Объединение Сетевых Карт Windows — Это функция, которая также известная как Балансировка Нагрузки и Обеспечение Отказоустойчивости (LBFO), позволяет группировать несколько установленных на компьютере сетевых адаптеров. Целями этого процесса является обеспечение доступности, предоставляя передачу трафика во избежание потери связи при отказе сетевого компонента, и включение агрегирования пропускной способности сети по нескольким сетевым картам. До Windows Server 2012 для реализации Объединения Сетевых Карт требовалось использование сторонних решений независимых поставщиков оборудования (IHV), но теперь это встроенное решение, которое работает с различными типами и производителями сетевых карт.
Конвергентные Сетевые Адаптеры (CNAs) — Это относится к сетевому оборудованию, которое объединяет сетевые технологии Ethernet с подключениями хранилища Fibre Channel по Ethernet. Целью этого объединения является сокращение затрат и пространства, используемого для оборудования, особенно в центрах обработки данных и облачных средах, где используются блейд-серверы.
6.2 Проблемы с мониторингом сетей Hyper-V
Мониторинг сети важен в производственных средах, поскольку сеть и/или сетевые подключения могут стать узким местом, которое может негативно повлиять на то, как виртуализированные рабочие нагрузки (приложения и службы) отвечают и выполняются. Из беседы с некоторыми специалистами, работающими в этой области с клиентами, имеющими хосты Hyper-V и кластеры хостов, развёрнутые в корпоративных средах, может возникнуть ряд различных проблем, которые могут затруднить мониторинг производительности сети Hyper-V.
Например, в то время как встроенный в Microsoft Монитор Производительности (perfmon.exe) — это, практически, готовый инструмент для сбора и анализа сетевого трафика, чтобы помочь определить возможные узкие места, существуют определённые общие ситуации в реальном мире, в которых Perfmon может потерпеть неудачу. Один из таких сценариев — это, когда есть конвергентное структурное решение DCB, включающее Сеть Хранения Данных Fibre Channel (FC), которая используется для хранилища Hyper-V. Если используются сторонние DCB-совместимые сетевые адаптеры Ethernet и DCB-совместимые коммутаторы, и в Windows Server 2012 установлена функция Моста для Центров Обработки Данных (команда PowerShell: Install-WindowsFeature Data-Center-Bridging), то необходимо знать, что Perfmon не осведомлён о DCB и не может контролировать сетевой трафик различных классов трафика, участвующих в таких сценариях.
Также важно знать, что Объединение Сетевых Карт Windows не имеет сведений или знаний о DCB на хосте. В результате этого, если на хосте создаётся любое объединение NIC, в котором используются сетевые адаптеры с поддержкой DCB, может произойти ухудшение производительности сети, что можно было ожидать от этой схемы. Также нет возможности настроить функцию DCB для Windows Server на сетевых адаптерах, которые используются для Hyper-V, т. к. включение DCB не влияет на какие-либо сетевые карты, привязанные к виртуальному коммутатору на хосте. Ситуация становится ещё более сложной, когда используются Конвергентные Сетевые Адаптеры (CNAs), что будет рассмотрено в следующей части статьи.
7. Производительность сети — Конвергентные Сетевые Адаптеры (CNAs)
В предыдущей части было начато рассмотрение проблемы, связанной с мониторингом производительности сети для хостов Hyper-V и кластеров в корпоративных средах. Были рассмотрены некоторых базовые сетевые концепции, которые имеют отношение к хостам Hyper-V промышленного уровня. Эти базовые концепции включают в себя Качество Обслуживания (QoS), Мост для Центров Обработки Данных (DCB), Прямую Передачу Данных (ODX), Объединение Сетевых Карт Windows и Конвергентные Сетевые Адаптеры (CNAs). Затем мы рассмотрели некоторые из трудностей, которые могут быть связаны с мониторингом производительности сетей хостов Hyper-V и кластера хостов, изучая то, как встроенный инструмент под названием «Монитор Производительности» (Perfmon.exe) в Windows Server 2012 не может контролировать сетевой трафик различных классов, участвующих при использовании сторонних DCB-совместимых сетевых Ethernet-адаптеров и DCB-совместимых коммутаторов и наличии установленной на компьютере-хосте функции Моста для Центров Обработки Данных (DCB) Windows Server 2012. В этой части углубимся в данную тему, рассмотрев то, как использование Конвергентных Сетевых Адаптеров (CNA-карт или CNAs) может ещё больше усложнить мониторинг производительности сети Hyper-V.
7.1 Понимание конвергентной сети
Конвергентная сеть имеет значение там, где разные типы сетевого трафика используют одну и ту же физическую сетевую инфраструктуру. Один из сценариев, где можно реализовать конвергентную сеть, — это с кластерами Hyper-V, которые обычно используют несколько различных типов сетевого трафика. Например, кластер хостов Windows Server 2012 R2 Hyper-V может генерировать следующие виды сетевого трафика:
- Управляющий трафик между хостами Hyper-V и инфраструктурой управления системами;
- Трафик рабочей нагрузки между внешними клиентами и виртуальными машинами, работающими на кластере хостов;
- Трафик хранения между хостами, виртуальными машинами и хранилищем;
- Трафик кластера для обмена данными между узлами кластера и общим хранилищем CSV.
Кроме того, иногда могут присутствовать следующие типы трафика:
- Трафик Динамической Миграций от Динамической Миграции виртуальных машин;
- Трафика Реплики от репликации виртуальных машин посредством Реплики Hyper-V.
Хотя большинство из вышеперечисленных видов трафика являются трафиком TCP/IP, трафик хранилища может быть файловым (используя SMB 3.0 по TCP/IP), либо блочным (Fibre Channel или iSCSI). Если сеть хранения данных (SAN) использует протокол Fibre Channel (FC), соединение с хостом может быть обеспечено с помощью хост-адаптера шины (HBA). Но с помощью Fibre Channel по Ethernet (FCoE) вы можете сжать FC-кадры для передачи непосредственно по Ethernet.
Для достижения такой конвергенции (комбинации) трафика TCP/IP и сжатого FC-трафика, и передачи обоих типов трафика по одной и той же сети Ethernet требуется Конвергентный Сетевой Адаптер (CNA). CNAs — это сетевые адаптеры, сочетающие в себе функциональность сетевого Ethernet-адаптера TCP/IP и хост-адаптера шины FC или iSCSI в одной карте, чтобы хосты Hyper-V могли подключаться как к локальным сетям Ethernet, так и к сетям хранения FC или iSCSI. Обычно CNA — это карты 10 Гбит/с, которые используются в блейд-серверах в средах центров обработки данных из-за ограниченного физического пространства для периферийных устройств, доступного в таких блейд-серверах. К популярным поставщикам CNA относятся QLogic и Broadcom.
7.2 Конвергентные Сетевые Адаптеры, Качество Обслуживания и производительность сети Hyper-V
Основная проблема с CNA заключается в том, что они передают свою совокупную пропускную способность сети в операционную систему. Таким образом, если в системе хостов блейд-серверов Hyper-V есть CNA-карта и вы пытаетесь контролировать пропускную способность сети, то CNA-карта часто будет отображаться для операционной системы Windows Server как обычная сетевая карта 10 Гбит/с. Несмотря на то, что некоторая часть пропускной способности карты отводится для передачи трафика хранения FC или iSCSI, до тех пор, пока мы имеем дело с Windows Server, это просто передача стандартного трафика Ethernet.
Проблема в том, что CNA-карты, как правило, предназначены для работы в связке с Мостом для Центров Обработки Данных (DCB) для обеспечения связи без потерь для Fibre Channel по Ethernet (FCoE). Уже известно, что не следует включать DCB ни на одной сетевой карте, связанной с виртуальным коммутатором на хосте Hyper-V. Если есть сетевая карта, привязанная к виртуальному коммутатору Hyper-V, то у сетевой карты не должно быть другого источника трафика, проходящего через неё, в противном случае любое управление полосой пропускания, которое вы попытаетесь выполнить (включая реализацию QoS сети), скорее всего, поломается, т.к. Hyper-V будет пытаться управлять каналом данных через коммутатор, как если бы Hyper-V владел всем трафиком. Результатом может быть ухудшение производительности сети для кластера в целом.
Кроме того, если вы попытаетесь реализовать QoS сети на уровне виртуального коммутатора Hyper-V или на уровне виртуальной машины, то не надо использовать какое-либо стороннее сетевое оборудование, которое разделяет сетевой трафик или пытается применить своё собственное QoS к трафику. И если используется какое-либо сетевое оборудование, которое разделяет трафик канала данных с трафиком разгрузки хранилища, тогда вы не сможете эффективно использовать QoS сети с Hyper-V.
Однако есть обходной путь решения этой проблемы и это использование статического QoS. Другими словами, можно использовать поставляемое поставщиком программное обеспечение, идущее вместе с CNA-картой, чтобы указать, какая часть пропускной способности должна быть доступна для трафика данных и для трафика хранилища. Например, можно настроить статическое QoS на карте 10 GbE CNA-карте на хосте Hyper-V так, чтобы 3 Гб было выделено для использования FCoE, в то время как остальные 7 Гб были доступны для операционной системы Windows Server в качестве доступных для других сетевых данных (т.е. управляющего трафика, трафика виртуальной машины и т.д.). Многие доступные сегодня CNA-карты позволяют провести разделение адаптера в BIOS так, чтобы он отображал указанную доступную пропускную способность вместо максимальной доступной пропускной способности.
7.3 Заключение и рекомендации
Ситуация с поднятой в статье темой довольно сложная и все ещё развивается. Частично проблема заключается в том, что Microsoft, кажется, не работает в этом направлении достаточно плотно с наиболее распространёнными решениями, встречающимися в реальном мире сетей дата-центров, а именно с Cicso, Dell, IBM и HP. Вместо этого Microsoft, похоже, проталкивает решение следующего поколения программно-определяемого хранилища (SDS) под названием Storage Spaces Direct в Windows Server 2016, которое использует Удалённый Доступ к Памяти (RDMA) и которое использует совместимые с RDMA сетевые карты производства Chelsio и Mellanox.
К сожалению, данное решение используют в своих центрах обработки данных немногие. Другими словами, когда общаетесь с крупными поставщиками систем хранения данных о производительности сети и доступности, часто получаете совсем другую перспективу, чем, когда разговариваете с Microsoft о том, каково их собственное видение и планы для «конвергентной инфраструктуры» дата-центров завтрашнего дня.
И поскольку технология, по-видимому, развивается гораздо быстрее, чем документация о лучших методах её использования, рекомендации, выпущенные несколько лет назад в отношении использования CNA в кластерах хостов Hyper-V, возможно, побудили некоторых клиентов внедрять решения на базе CNA в средах блейд-серверов, хотя это, на самом деле, не является предпочтительным решением. Поэтому, если в настоящее время вы используете адаптеры CNA в кластере хостов Hyper-V на базе блейд-серверов, то можно перепроверить производительность сети кластера под большой нагрузкой, чтобы увидеть, не улучшит ли статическое назначение полосы пропускания производительность по сравнению с текущей настройкой.
Редакция Практики